
В данном руководстве представлены рекомендации по планированию и статистическому анализу селекционных полевых испытаний, ориентированные на селекционеров, не имеющих доступа к постоянной поддержке биостатистов или биометристов.
Источник: https://excellenceinbreeding.org/sites/default/files/manual/MET-practical-guidelines-Feb-2022_0.pdf
Перевод: Надежда Долматова, dolmatova.sk@gmail.com
Введение
Полевые испытания используются для оценки генотипов по ряду целевых признаков, а также для оценки или прогнозирования их генетической ценности. Измерения различных типов генетической ценности необходимы для выбора родителей с целью улучшения популяции и сортов-кандидатов для создания будущих коммерческих сортов и гибридов. Таким образом, хорошо спланированные полевые испытания и надежный статистический анализ данных закладывают основу для высоких показателей генетического прогресса (genetic gain). Учитывая большое разнообразие экспериментальных схем (дизайнов) и сложность различных моделей анализа данных, оставаться в курсе передовых практических подходов может быть непросто. В идеальной ситуации, планирование опытов и анализ их результатов планируются со специалистом по биометрии. Однако многие селекционные программы не имеют доступа к постоянной биометрической поддержке. Поэтому селекционерам приходится самостоятельно разрабатывать схемы (дизайн) опытов и анализировать данные – обычно помимо множества других задач – что часто требует прагматичного и эффективного по времени подхода к проведению полевых испытаний.
Это руководство содержит рекомендации по планированию и анализу данных селекционных испытаний. Оно помогает проводить надежные и точные полевые испытания, избегая серьезных ошибок. Особое внимание уделяется испытанию генотипов на ранних и поздних этапах селекционной программы, а также различиям между испытаниями в пределах одной локации и в нескольких локациях. Руководство включает советы по работе с контрольными образцами и повторностями, анализу данных полевых испытаний в разных локациях и моделированию взаимодействия генотипа с окружающей средой (GxE).
Рекомендации по организации селекционных испытаний
Различные селекционные цели требуют разных схем (дизайнов) опытов
Цели селекционных испытаний различаются на ранних и поздних этапах селекционной программы.
На ранних этапах селекционной программы обычно тестируются сотни или тысячи генотипов, при этом доступно ограниченное количество семян или посадочного материала, и это происходит в одной или нескольких локациях. Часто невозможно использовать повторности для некоторых или всех генотипов. Основная цель на этом этапе – выбрать генотипы, которые наилучшим образом улучшают популяцию по ключевым признакам. В селекционных программах, нацеленных на сокращение времени между поколениями, ранние стадии испытаний выполняют две задачи:
- Отбор родителей для обеспечения высокого и стабильного генетического прогресса в будущих скрещиваниях
- Перевод лучших генотипов на следующие стадии испытаний
На поздних стадиях селекционных испытаний обычно тестируется относительно небольшое количество лучших генотипов в разных локациях. Этот процесс известен как испытания в нескольких локациях (multi-environment trials, MET). Основная цель этих испытаний – оценить истинную ценность тестируемых генотипов в целевой выборке локаций (target population of environments, TPE) по всем признакам, включенным в профиль продукта. В селекционных программах, ориентированных на короткие интервалы между поколениями, поздние стадии испытаний фокусируются на выборе будущих коммерческих сортов или гибридов. Хотя отбор родителей на поздних стадиях испытаний остается распространенной практикой во многих селекционных программах, мы рекомендуем применять стратегии, которые предполагают строгий отбор новых родителей на ранних стадиях. Отбор кандидатов на сорта обычно проводится по сравнению с одним или несколькими эталонными сортами.
Подход к планированию испытаний на ранних и поздних стадиях селекционной программы обычно отличается. Для управления разным количеством генотипов, количеством повторностей и локаций на этих стадиях используются различные схемы испытаний в нескольких локациях (MET) и схемы испытаний в пределах одной локации, как показано в Таблице 1.
Дизайн испытаний в нескольких локациях (МЕТ) определяется количеством и типом мест проведения тестирования. Целью МЕТ является получение точного прогноза истинных характеристик генотипа в рамках всей целевой выборке локаций (TPE) на основе отобранных тестовых локаций.
Дизайн испытаний в пределах одной локации характеризуется количеством тестируемых генотипов, числом (не)полных повторностей и распределением генотипов в пределах этих повторностей. Целью испытания в пределах одной локации является точное предсказание истинной ценности генотипа в конкретном месте проведения опыта.
| Дизайн испытаний в нескольких локациях (МЕТ) | Дизайн испытаний в пределах одной локации |
| – Одна локация – Несколько локаций (испытание в нескольких средах; MET) | – С полным набором повторностей (Fully replicated) – С частичным повторением (P-rep) – Без повторения (Unreplicated) |
В данном руководстве представлены рекомендации по планированию и анализу селекционных испытаний на ранних и поздних стадиях селекционной программы. Хотя строгого разделения между ранними и поздними стадиями испытаний нет, авторы руководства убеждены, что такая классификация помогает селекционерам получить общие рекомендации о том, как эффективно и точно проводить полевые испытания на различных этапах селекционной программы.
Дизайн испытаний в нескольких локациях (МЕТ)
Испытания в разных локациях с целью увеличения повторяемости генотипа
Что такое повторяемость генотипа?
Повторяемость (repeatability) – стабильность проявления, корреляция между измерениями одной и той же особи (стр. 182, Фолконер, Д.С. Введение в генетику количественных признаков / Д. С. Фолконер; Пер. с англ. А. Г. Креславского, В. Г. Черданцева; Под ред. Л. А. Животовского. – Москва : Агропромиздат, 1985.)
Цель проведения испытаний в нескольких локациях заключается в получении точного прогноза истинной ценности генотипа в рамках всей TPE. Для достижения этого генотипы должны быть протестированы в максимально возможном количестве мест.
Из уравнения наследуемости в широком смысле (Уравнение 1) мы знаем, что увеличение количества мест проведения испытаний всегда выгоднее, чем увеличение количества повторностей внутри одной локации (при условии четко определенной целевой выборки локаций, TPE). В частности, мы видим, что:
- Увеличение количества локаций (nEnv) увеличивает наследуемость (H2) за счет уменьшения дисперсии взаимодействия GxE (σ2GxE) и остаточной дисперсии (σ2e).
- Увеличение количества повторностей внутри локации (nRep) увеличивает наследуемость (H2) только за счет уменьшения остаточной дисперсии (σ2e).
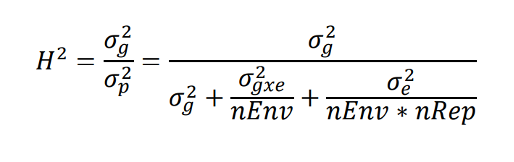
Где:
H2 – наследуемость в широком смысле (повторяемость генотипа)
σ2g – генетическая дисперсия
σ2p – фенотипическая дисперсия
σ2gxe – дисперсия взаимодействия генотип-среда
σ2e – остаточная дисперсия
nEnv – количество локаций (местоположения или комбинаций год-локация)
nRep – количество потернистей внутри локации
Увеличение повторяемости более или менее эквивалентно увеличению точности отбора (selection accuracy). Однако увеличение повторяемости в результате испытаний в большем количестве локаций не является линейным и быстро выйдет на плато в четко определенном наборе TPE, как показано на рисунке 1.
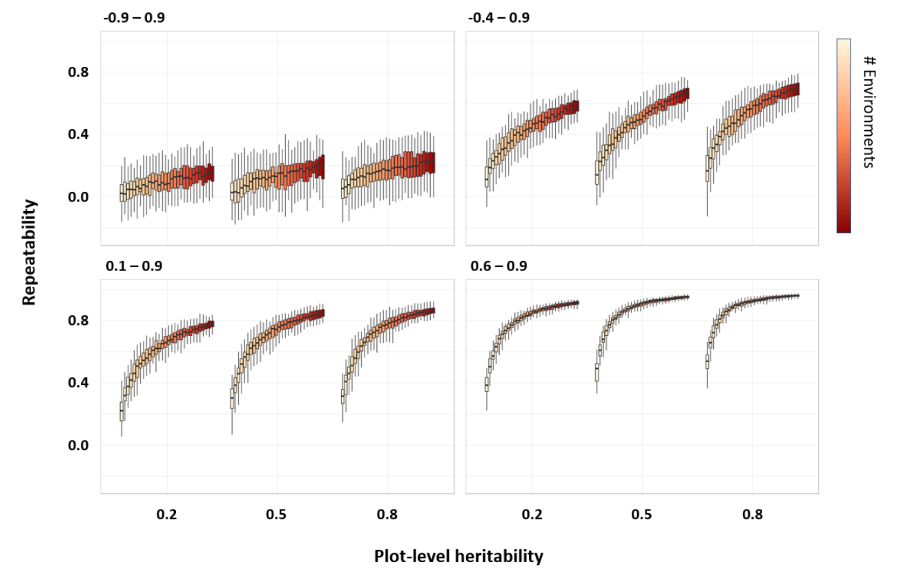
Для целевой выборки локаций (TPE) с умеренной до высокой генетической корреляцией между локациями мы приходим к следующим выводам:
- Когда количество мест проведения испытаний невелико (например, 5 или меньше), проведение тестирования в дополнительной локации может значительно увеличить повторяемость.
- Если количество локаций уже достаточно велико (например, 15 или больше), дополнительное увеличение повторяемости будет незначительным. В таком случае, затраты на тестирование в дополнительной локации могут оказаться неоправданными.
Для целевой выборки локаций (TPE), включающей локации с умеренной и высокой отрицательной корреляцией, мы приходим к следующим выводам:
- Увеличение количества мест проведения испытаний приводит только к незначительному росту повторяемости. Достичь высокой повторяемости может быть сложно или даже невозможно.
- Это может свидетельствовать о том, что TPE определена недостаточно четко (слишком широкий охват), и стратегия отбора на основе среднего значения генотипа по всей TPE не является оптимальной для выявления наиболее перспективных сортов.
Общие рекомендации по эффективному планированию испытаний в нескольких локациях
В целом, увеличение количества локаций оказывается более выгодным, чем увеличение числа повторностей в каждой локации. Это правило применимо как к ранним, так и к поздним стадиям селекционной программы. Однако, в зависимости от вашей текущей стратегии испытаний, могут потребоваться различные подходы для оптимизации дизайнов в разных локациях:
- Если есть возможность перераспределить повторности, увеличьте количество локаций и сократите число повторностей в каждой из них. Проведение испытаний в нескольких локациях критично для точного отбора родителей.
- Сокращайте количество повторностей внутри локаций только в том случае, если эти повторности можно перераспределить в дополнительные локации. Если количество локаций увеличить невозможно, использование нескольких повторностей внутри одной локаций по-прежнему повышает повторяемость (Примечание: хотя тестирование нескольких повторностей в каждой локации по-прежнему повышает повторяемость, использование более 3-4 повторностей в каждом месте редко оправдано).
- Если текущее количество локаций невелико (например, до 5), попробуйте добавить больше локаций для проведения испытаний. Особенно для малых селекционных программ с ограниченным числом мест испытаний, добавление даже одной дополнительной локации может значительно улучшить повторяемость.
- При большом количестве локаций (например, 10 и более) дальнейшее увеличение повторяемости и генетического прогресса будет ограничено, поэтому ресурсы лучше направить в другие направления.
Традиционные подходы к испытаниям в нескольких локациях обычно предусматривают тестирование каждого генотипа по крайней мере один раз в каждой локации. В таких случаях число локаций для проведения испытаний ограничено общим числом доступных повторностей для каждого генотипа. Однако, схемы “разреженного” тестирования (Sparse testing designs) дают возможность тестировать генотипы в большем числе локаций, чем это позволяет количество доступных повторов на генотип.
Sparse-схемы: частный случай испытаний в нескольких локациях
Sparse-схемы в экспериментальном дизайне – это метод проведения полевых испытаний одновременно в нескольких локациях (MET), где не каждый генотип проверяется во всех локациях (см. рис. 2). Эти схемы дают возможность проводить испытания в большем количестве локаций, чем количество повторностей, доступных для одного генотипа. Такой подход позволяет более широко анализировать TPE и улучшать повторяемость. Sparse-схемы эффективны как на начальных, так и на заключительных этапах селекционной программы. Но они особенно ценны на ранних стадиях, когда количество семян или посадочного материала ограничено. Помимо этого, такие схемы идеально подходят для «совместной» селекции (participatory breeding), когда каждый сельхозтоваропроизводитель может протестировать только небольшую часть сортов-кандидатов.
Что такое “менделевская выборка”?
Термин «менделевская выборка» (Mendelian sampling) — это концепция генетики, которая относится к случайным вариациям генетического состава, которые особь наследует от своих родителей. Эта изменчивость обусловлена случайным набором генов при образовании гамет и последующей комбинацией этих гамет при оплодотворении. Этот термин представляет собой уникальные генетические различия, которые не объясняются средним генетическим вкладом родителей. По сути, это «генетическая лотерея», в которой наследуются определенные аллели (варианты генов).
Планирование испытаний с использованием sparse-схем может быть сложным. Необходимо обеспечить равномерное распределение генотипов по всем локациям и связать их через матрицу геномных отношений (genomic relationship matrix). Это нужно для прогнозирования их эффективности в тех локациях, где они не испытывались. Важно использовать именно матрицу геномных отношений, а не родословную, так как последняя не учитывает “менделевскую выборку”. Если единицей оценки является генотип, то для получения информации о его эффективности в нескольких локациях необходимо протестировать сам генотип во всех локациях. Но при использовании маркерного аллеля как единицы оценки, большинство или все маркерные аллели будут протестированы во всех локациях, даже если отдельные генотипы где-то не тестируются. Таким образом, можно предсказать среднюю эффективность генотипа во всех локациях, исходя из его маркерного генотипа и связей с другими генотипами.
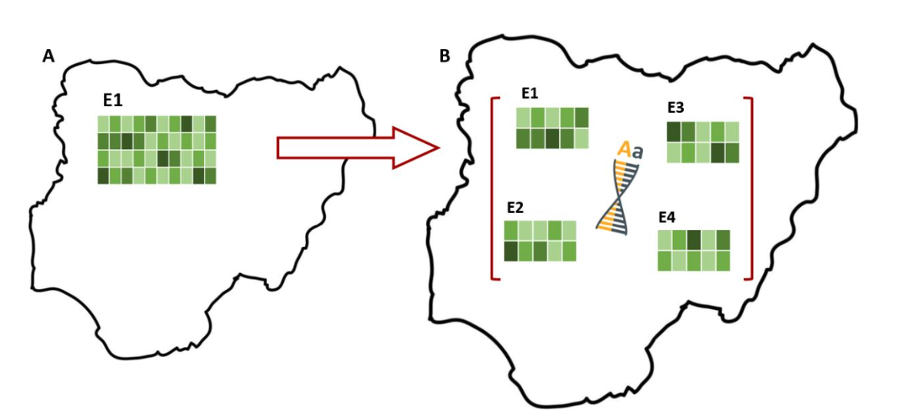
Sparse схемы, используемые на ранних этапах селекционной программы, создают надежную базу для точного отбора и ускорения сокращения интервала между поколениями в программах с геномным прогнозированием. Если вы рассматриваете внедрение sparse-схем, мы настоятельно рекомендуем проконсультироваться со специалистом по биометрии перед планированием соответствующих проектов.
Дизайн исследования в пределах одной локации
Уровни репликации в селекционных испытаниях в пределах одной локации
Существует огромное количество схем (дизайнов) испытаний в пределах одной локации, они используются для оптимизации полевых опытов с учетом различного количества генотипов и повторностей, предположений о гетерогенности поля, различных (неполных) размеров и расположений блоков, а также различных исследовательских вопросов. Это затрудняет выбор подходящей схемы опыта для каждого этапа селекционной программы. Оптимальное планирование полевых испытаний рекомендуется осуществлять в консультации с биометрическим специалистом. В условиях отсутствия постоянной биометрической поддержки требуется применение прагматичного подхода.
В зависимости от уровня репликации, схемы испытаний в пределах одной локации можно разделить на три типа:
- С полным набором повторностей (Fully replicated)
- С частичным повторением (P-rep)
- Без повторения (Unreplicated)
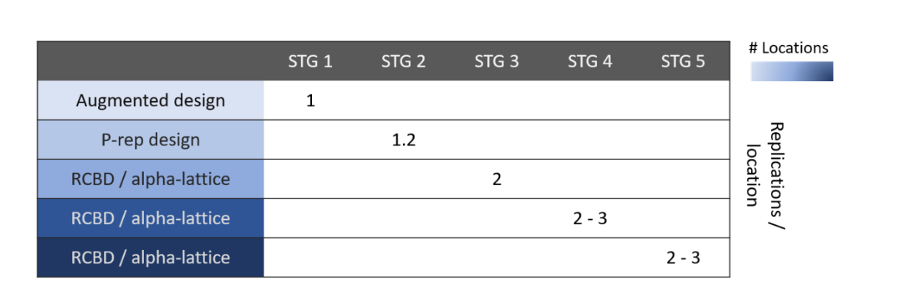
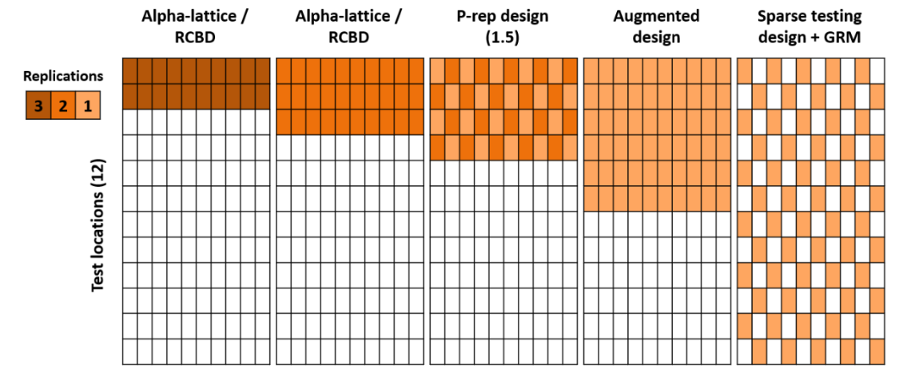
На поздних стадиях исследований часто используются схемы с полным наборов повторностей, такие как рандомизированный полный блочный дизайн (RCBD) или дизайн с неполным блоком (incomplete block). На ранних этапах обычно встречаются p-rep схемы или без повторностей в одной или нескольких локациях (см. рис. 3). Однако важно понимать, что такая категоризация не является строгой. Например, частично p-rep схемы или схемы без повторностей также могут быть эффективны на поздних стадиях тестирования.
Общие рекомендации по эффективному планированию испытаний в пределах одной локации
Часто возникает выбор между количеством тестируемых повторностей в одной локации (дизайн в пределах одной локации) и количеством тестовых локаций (дизайн в нескольких локациях). Как видно из предыдущего текста, проведение испытаний в большем числе локаций обычно предпочтительнее, чем увеличение числа повторностей в меньшем количестве мест. Таким образом, хороший дизайн в пределах одной локации должен обеспечивать такое количество повторностей, чтобы можно было тестировать образцы в как можно большем количестве мест.
Рекомендации по проектированию схем испытаний в пределах одной локации на ранних стадиях селекционной программы
Выбор эффективной схемы (дизайна) для селекционных испытаний на ранних стадиях в пределах одной локации зависит от количества доступных повторов для каждого генотипа. Вы можете использовать:
- Дополненный дизайн (augmented design) с 5–10% контрольных делянок, если генотипы не могут быть воспроизведены в нескольких повторностях.
- Дизайн с частичным повторением (p-rep) с уровнем репликации 5–10%, если некоторые генотипы могут быть высажены в нескольких повторностях.
- Дополненный или p–rep дизайн в нескольких локациях, если все генотипы могут быть реплицированы. Если используется схема p-rep, разные генотипы могут быть реплицированы во всех локациях (если это возможно).
- Разреженный дополненный дизайн (sparse augmented design) или разреженный p-rep дизайн (sparse p-rep design) с несколькими повторностями для дальнейшего увеличения количества мест тестирования. Эти методы позволяют проводить испытания в нескольких локациях, даже если отдельные генотипы не поддаются множественному повторению. Важно отметить, что для sparse-тестирования требуется использование матрицы геномных отношений (см. раздел «Sparse-тестирование»).
Для augmented и p-rep схем рандомизация частично реплицированных генотипов и/или контрольных участков обычно достаточна для создания надежного дизайна. Хотя более сложные дизайны могут быть более эффективны, разница зачастую небольшая и не имеет большого значения на практике (согласно Hoefler и др., 2020). Тем не менее, оптимизированные дизайны обычно не требуют дополнительных расходов, поэтому их использование рекомендуется, если это возможно.
Современные программные решения, которые создают оптимальные или почти оптимальные схемы опытов на основе математических моделей
- OD (Butler 2019): R пакет (бесплатно).
- DiGGer (Coombes 2020): R пакет (бесплатно).
- CycDesigN (VSN): отдельное ПО; реализовано в программном комплексе «Breeding Management System» (BMS) (лицензия)
- FielDHub: R пакет (бесплатно).
Примеры создания схем опытов с использование пакета FielDHub можно посмотреть здесь.
Рекомендации для составления схем испытаний на поздних стадии селекционной программы
На поздних этапах селекционной программы обычно имеется достаточно ресурсов для проведения испытаний с несколькими повторностями в различных локациях. Если в каждой локации возможно тестировать все генотипы хотя бы в двух повтореностях, можно использовать следующий общепринятый план:
- В зависимости от числа генотипов и предполагаемой неоднородности поля, рандомизированный полный блочный дизайн (RCBD) или дизайн с неполным блоком, например alpha-lattice, может быть эффективным решением для одной локации.
- Современные программные решения, которые создают оптимальные или почти оптимальные схемы на основе математических моделей могут еще больше повысить эффективность схем с полным набором повторностей (FielDHub и др.).
- Никаких дополнительных контрольных образцов для измерения пространственной изменчивости не требуется.
- Тестирование более 3 или 4 повторностей в одной локации обычно не является эффективным, и поэтому его следует избегать.
- Если количество тестовых локаций меньше 8–10[1], то можно сократить количество повторов на одну локацию, чтобы расширить тестирование на большее количество мест. Применение sparse-тестирования целесообразно, когда общее количество повторностей на генотип не позволяет тестировать все генотипы во всех локациях или когда ресурсы для проведения испытаний ограничены.
[1] Это приблизительное значение. Как показано на рисунке 1, повторяемость (и, следовательно, точность выбора) приближается к плато с увеличением числа локаций. Эта тенденция зависит от генетических корреляций между тестируемыми локациями (TPE). Если TPE четко определен, может быть достаточно менее 8–10 локаций. Хотя оптимальный баланс между повторяемостью и наличием ресурсов для проведения испытаний зависит от ситуации, 8-10 локаций могут быть эталонным числом для многих программ селекции CGIAR.
Сколько нужно контрольных образцов?
Контрольные образцы в селекционных испытаниях служат нескольким целям. Селекционеры могут использовать в качестве контрольных образцов: 1) разные эталонные сорта для сравнения в процессе создания новых сортов / гибридов; 2) адаптивные генотипы для сравнения результатов испытаний в разных локациях и отслеживания генетического прогресса; 3) реплицированные контрольные образцы для оценки остаточной дисперсии.
В данном разделе мы предлагаем рекомендации по стратегиям использования контрольных образцов для оценки остаточной дисперсии. Учтите, что эти рекомендации основаны на использовании линейной смешанной модели для анализа данных испытаний (см. далее) и не применимы при использовании традиционной ANOVA-модели. Подробности по оптимизации работы с контрольными образцами смотрите в руководстве EiB «Оценка альтернативных метрик генетической ценности».
- В схемах без использования повторностей (например, augmented дизайн) используйте 5-10% участков для реплицированных контрольных делянок. Контрольные образцы можно распределять по делянкам случайным образом. Можно также использовать модельный дизайн для проверки распределения. Например, исследование на ранней стадии селекционной программы из 1000 делянок может включать 950 нереплицированных генотипов и 50 участков, распределенных между 3-4 контрольными образцами. На более поздней стадии селекционной программы испытание из 50 участков может включать 40 нереплицированных генотипов и 10 участков, распределенных между 4-5 контрольными образцами.
- P-rep схемы: используйте 5-10% участков для генотипов, которые можно разместить в повторностях. Эти генотипы могут быть случайным образом распределены по делянкам. Можно использовать (модельный) дизайн для дополнительной проверки распределения. Дополнительные контрольные образцы не требуются для получения оценки остаточной дисперсии. В многолокационных p-rep дизайнах, повторяйте разные генотипы в разных локациях (по возможности). Например, исследование на ранней стадии с использованием p-rep схемы состоящее из 1000 делянок, может включать 800 нереплицированных генотипов (800 делянок) и 100 реплицированных генотипов (200 делянок). Для более поздних стадий: p-rep дизайн, состоящий из 50 участков, может протестировать 30 нереплицируемых генотипов (30 делянок) и 10 реплицированных генотипов (20 делянок).
- Схемы с полным набором повторностей (RCBD, alpha-lattice): остаточная дисперсия оценивается на основе всех реплицированных генотипов. Дополнительные контрольные образцы не требуются.
Анализ данных полевых испытаний и оценка взаимодействия генотипа с окружающей средой (GxE)
Линейные смешанные модели: золотой стандарт анализа данных полевых испытаний
Все рекомендации в этом руководстве основаны на использовании линейных смешанных моделей для анализа данных полевых испытаний. Линейные смешанные модели обеспечивают гибкий и точный анализ сложных экспериментальных данных, что делает их эталонным стандартом в статистическом анализе селекции растений.
По сравнению с традиционной фиксированной линейной моделью (ANOVA), линейные смешанные модели имеют ряд преимуществ:
• Они позволяют одновременно оценивать фиксированные эффекты и прогнозировать случайные эффекты.
• Могут обрабатывать несбалансированные (неполные) данные, когда не все генотипы тестируются во всех местах/годах или тестируются с разным числом повторов.
• Обеспечивают гибкие структуры дисперсии и ковариации для анализа генетических и негенетических эффектов, а также взаимодействия генотипа с окружающей средой.
• Позволяют учитывать корреляции между генотипами, используя матрицу родословных или геномных отношений.
Среди популярных бесплатных и лицензированных программных решений для работы с линейными смешанными моделями:
• ASReml-SA (Gilmour и др., 2021): автономное ПО, нужна лицензия.
• ASReml-R (Butler, 2020): пакет для R, лицензированный.
• sommer (Covarrubias-Pazaran, 2018): пакет для R, бесплатный и с открытым исходным кодом.
• lme4 (Bates и др., 2015): пакет для R, бесплатный и с открытым исходным кодом.
• SAS (SAS Institute Inc.): автономное ПО, нужна лицензия.
Общие рекомендации по анализу данных полевых испытаний
Хотя выбор наиболее подходящей модели всегда зависит от конкретного набора данных, существуют общие рекомендации, которые служат основой для эффективного и надежного моделирования. Тем не менее, мы рекомендуем планировать и анализировать ваши полевые испытания со специалистом по биометрии, так как здесь невозможно предоставить исчерпывающий обзор.
Рекомендации по анализу данных полевых испытаний в пределах одной локации
• Сорта-кандидаты (нереплицированные и реплицированные) моделируются как случайные эффекты, что соответствует целям отбора на ранних этапах исследования и позволяет использовать матрицу родословных или геномных связей (AB Smith, Cullis и Thompson, 2005).
• Контрольные образцы моделируются как фиксированные эффекты и исключаются при оценке генетической дисперсии, так как они не являются частью селекционной популяции.
• Факторы, связанные с блоком (например, блоки, строки, столбцы), обычно моделируются как случайные эффекты, кроме случаев с очень малым числом уровней фактора, когда их можно моделировать как фиксированные эффекты. Важно отслеживать информацию о строках и диапазонах (столбцах).
• Пространственный компонент может улучшить моделирование остаточных эффектов, предполагая корреляционную структуру остатка по всему полю. Двумерная авторегрессионная модель (AR1:AR1; Gilmour et al. 1997) доказала свою эффективность и надежность.
• Включение случайной ошибочной переменной к коррелированной остаточной переменной (например, AR1:AR1) может улучшить соответствие модели.
• Целесообразно включать факторы блока, корреляционные структуры и случайную ошибочную переменную только если они улучшают соответствие модели. На практике они часто улучшают модель и редко ухудшают соответствие. Рекомендуется сравнивать различные модели, если это возможно.
Общие замечания по анализу данных полевых испытаний в нескольких локациях (MET) и моделированию взаимодействия генотипа с окружающей средой.
Анализ испытаний в нескольких локациях более сложен, чем анализ испытаний в пределах одной локации. Хотя одни и те же рекомендации применимы к анализу каждой локации в отдельности (комбинация год-локация), объединение данных из нескольких локаций с использованием одноэтапного или двухэтапного подхода требует подходящей модели взаимодействия GxE. Подробное введение в моделирование эффектов взаимодействия GxE описано в в работах van Eeuwijk et al. (2001), Smith, Cullis, and Thompson (2005), and Smith and Cullis (2018).
Наиболее используемые модели взаимодействия GxE включают:
- Модель со сложной симметрией (Рис. 5А)
- Неструктурированная модель (Рис. 5Б)
- Факторно-аналитическая модель (ФА модель)
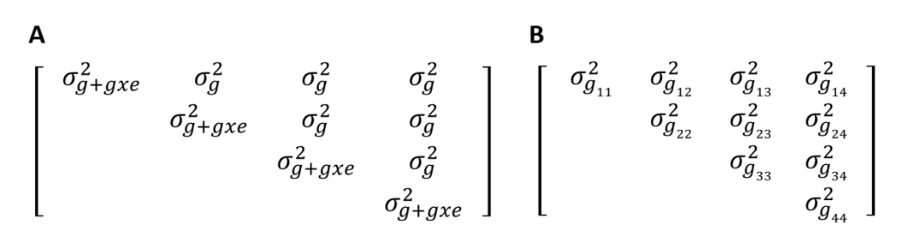
Модель со сложной симметрией удобна для анализа данных MET, если допустимо предположить одинаковую генетическую дисперсию и дисперсию взаимодействия GxE во всех локациях, а также одинаковую генетическую ковариацию между всеми локациями. Хотя предположение о однородных дисперсиях часто не реалистично, модель со сложной симметрией может служить базовой моделью и давать первое приближение о величине дисперсии взаимодействия GxE. Проще говоря, эта модель упрощает ситуацию, предполагая, что все генотипы одинаково реагируют на изменения окружающей среды. Это означает, что она не учитывает возможность того, что некоторые генотипы могут быть действительно хороши в одной среде, но плохи в другой, в то время как другие могут быть хорошо проявляться в разных средах.
Неструктурированная модель предусматривает уникальную генетическую дисперсию для каждой локации и уникальную генетическую дисперсию для каждой пары локаций. Это обеспечивает реалистичное представление испытаний в разных локациях и позволяет точно прогнозировать результаты в определенной локации. Но при большом количестве локаций расчеты в рамках этой модели становятся сложной задачей и могут привести к сингулярностям из-за множества оцениваемых компонентов дисперсии, что может вызвать проблемы с сходимостью модели. Эта модель не допускает такого упрощения, как модель со сложной симметрией, и позволяет каждой комбинации генотипа и окружающей среды иметь свой собственный уровень производительности. Эта модель более гибкая, поскольку она может отражать более сложные взаимосвязи между генотипами и средой.
Факторно-аналитические модели предлагают удачный компромисс между сложностью, эффективностью и достоверностью модели. Они позволяют аппроксимировать неструктурированную модель интуитивно, требуя гораздо меньше компонентов дисперсии для оценки. Благодаря этому факторно-аналитические модели стали очень популярны и часто являются предпочтительным выбором. Однако их интерпретация более сложна и требует определенного опыта.
К сожалению, не существует универсального подхода к моделированию, который позволял бы стандартизировать анализ данных полевых испытаний. Чтобы найти “лучший” метод, необходимо сравнивать разные модели, выбирая ту, которая обеспечивает как точность, так и вычислительную эффективность. Кроме того, цель полевого испытания также играет роль. Прогнозирование производительности генотипа в различных условиях потребует другой модели, чем прогнозирование средней производительности генотипа по всей TPE. Поэтому анализ испытаний в нескольких локациях лучше всего выполнять опытному специалисту по биометрии.
Матрица геномных отношений: смена парадигмы
Полногеномное генотипирование и анализ связей на основе маркеров радикально преобразили методы селекции растений. Хотя матрица геномных отношений рассматривается в основном как необходимое условие для стратегий геномной селекции, ее также можно использовать[2] для улучшения различных компонентов селекционной программы, полевых испытаний и их анализа.
При использовании маркерной информации для оценки селекционного материала, в качестве единицы оценки выступает маркерный аллель, а не отдельный генотип растения. Это ключевой момент для генетической оценки: особи с высоким процентом совпадающих маркерных аллелей считаются близко родственными. Такие родственные особи можно рассматривать как частичные повторности, и высокое геномное сходство позволяет нам извлекать из них дополнительные данные. Это особенно ценно на начальных этапах селекционной программы, где индивидуальные генотипы растений редко повторяются. Внедрение матрицы геномных связей позволяет использовать данные от многих близко родственных особей в течение всего полевого испытания.
[2] Информация о маркерах может использоваться либо на уровне отдельных маркеров (RR-BLUP; прогнозирование эффектов отдельных аллелей маркеров), либо с использованием отношений на основе маркеров (G-BLUP; все аллели маркеров используются для прогнозирования отношений между особями). Поскольку обе модели эквивалентны (при определенных условиях), здесь они используются как взаимозаменяемые.
Тестирование одной популяции в единственной локации может значительно улучшить повторяемость эксперимента и точность отбора. Объединение данных от скрещиваний разных поколений, проведенных в различных локациях и годах, позволяет создать тренировочную популяцию, лежащую в основе эффективной стратегии геномного отбора. Это приводит к повышению точности отбора и ускорению селекционного процесса, что является лишь частью многочисленных преимуществ.
Для большинства видов уже доступны платформы генотипирования средней плотности с несколькими тысячами маркеров, которые становятся все более доступными. Использование геномной информации может изменить правила игры и стать ключевым фактором увеличения генетического прогресса в селекционной программе.
Источники
- Bates D., Mächler M., Bolker B., Walker S. (2015) “Fitting Linear Mixed-Effects Models Using Lme4.” Journal of Statistical Software 67 (1). https://doi.org/10.18637/jss.v067.i01.
- Butler D. (2019) Od: Generate Optimal Experimental Designs. R Package Version 2.0.0.
- Butler D. (2020) Asreml: Fits the Linear Mixed Model. R Package Version 4.1.0.143. www.vsni.co.uk.
- Grogan H. (2020) DiGGer: DiGGer Design Generator under Correlation and Blocking. R Package Version 1.0.5. http://www.vsni.co.uk http://nswdpiobion.org/austatgen/software.
- Covarrubias-Pazaran G.E. (2018) “Software Update: Moving the R Package Sommer to Multivariate Mixed Models for Genome-Assisted Prediction.” Preprint. Genetics. https://doi.org/10.1101/354639.
- Eeuwijk F.A. van, Cooper M., DeLacy I.H., Ceccarelli S., Grando S. (2001) “Some Vocabulary and Grammar for the Analysis of Multi-Environment Trials, as Applied to the Analysis of FPB and PPB Trials.” Euphytica 122 (3): 477–90. https://doi.org/10.1023/A:1017591407285.
- Gilmour A.R., Cullis B.R., Verbyla A.P. (1997) “Accounting for Natural and Extraneous Variation in the Analysis of Field Experiments.” Journal of Agricultural, Biological, and Environmental Statistics 2 (3): 269. https://doi.org/10.2307/1400446.
- Gilmour A.R., Gogel B.J., Cullis B.R., Welham S.J., Thompson R. (2021) ASReml User Guide Release 4.2 Functional Specification, VSN International Ltd, Hemel Hempstead, HP2 4TP, UK, www.vsni.co.uk.
- Hoefler R., González-Barrios P., Bhatta M., Nunes J.A.R., Berro I., Nalin R.S., Borges A., et al (2020) “Do Spatial Designs Outperform Classic Experimental Designs?” Journal of Agricultural, Biological and Environmental Statistics 25 (4): 523–52. https://doi.org/10.1007/s13253-020-00406-2.
- Smith AB, Cullis BR, Thompson R (2005) “The Analysis of Crop Cultivar Breeding and Evaluation Trials: An Overview of Current Mixed Model Approaches.” The Journal of Agricultural Science 143 (6): 449–62. https://doi.org/10.1017/S0021859605005587.
- Smith AB, Cullis BR (2018) “Plant Breeding Selection Tools Built on Factor Analytic Mixed Models for Multi-Environment Trial Data.” Euphytica 214 (8): 143. https://doi.org/10.1007/s10681-018-2220-5.
- VSN International Ltd. “CycDesignN”.
- SAS Institute Inc., Cary, NC, USA. “SAS”.